Miswag Engineering Blog
Welcome to Miswag Engineering, where we share the latest insights on technology, product development, and innovation.

Data EngineeringApr 15, 2026
Loading Large Relational Database Tables Into an Analytics Warehouse Without Blocking Production
A chunked, memory-efficient full-load pattern for replicating large relational database tables into an analytics warehouse using query-based extraction and data orchestrator pipelines. Covers keyset pagination, batch sizing, memory management, and production-safe extraction — no CDC, binlog, or replica required.
By Hameed Mahmood Salih
Data ReplicationETL
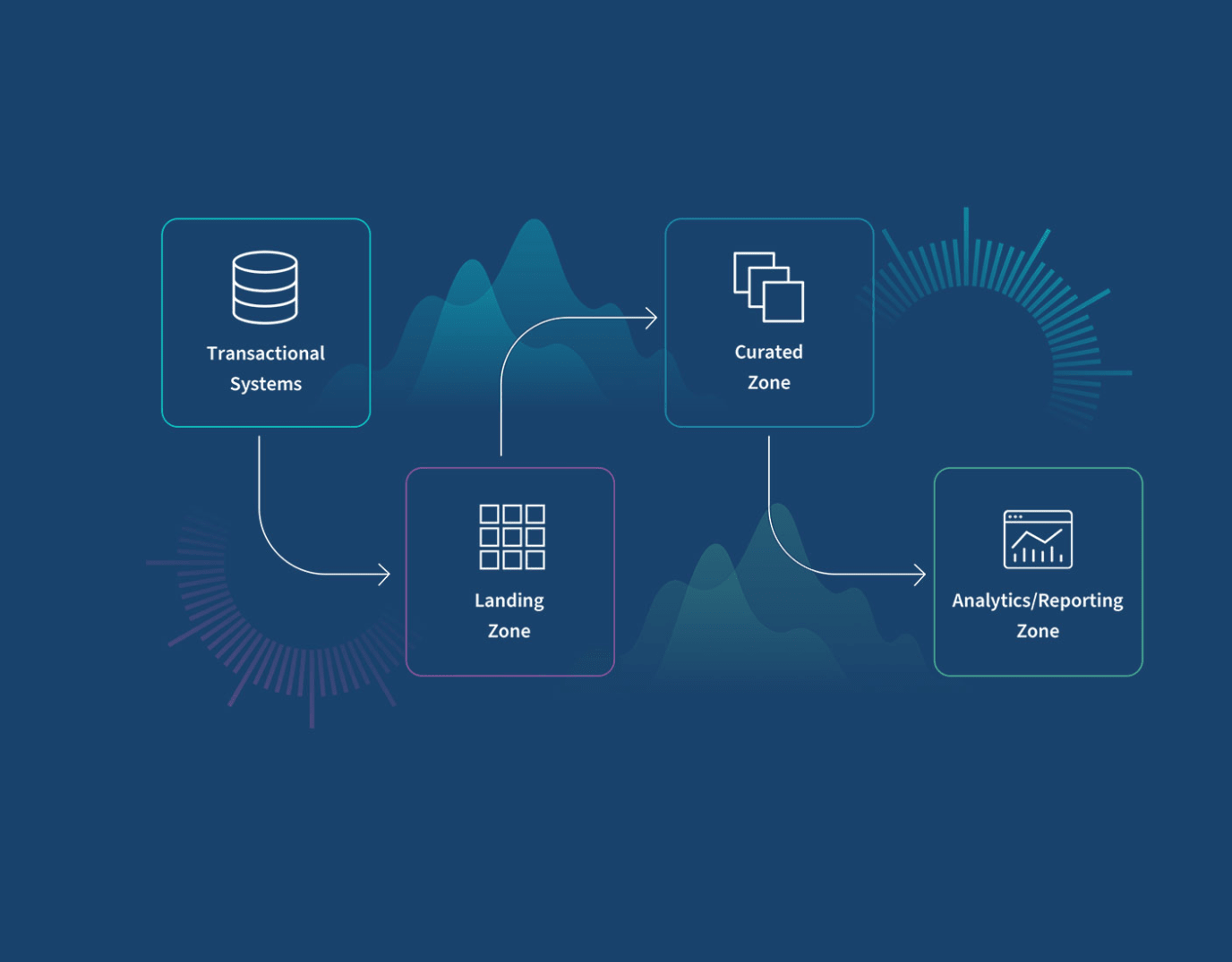
Data EngineeringMar 4, 2026
Over-Partitioning Can Kill Your Analytics Warehouse Performance and Inflate Your Costs
Choosing too fine a partition granularity in a columnar analytics warehouse silently accumulates memory pressure through part metadata overhead, merge churn, and allocator fragmentation. This article explains why over-partitioning happens, how the three cost mechanisms compound each other, and how switching to a coarser partition period eliminates the problem — without changing a single query.
By Hameed Mahmood Salih
PartitioningMemory Optimization
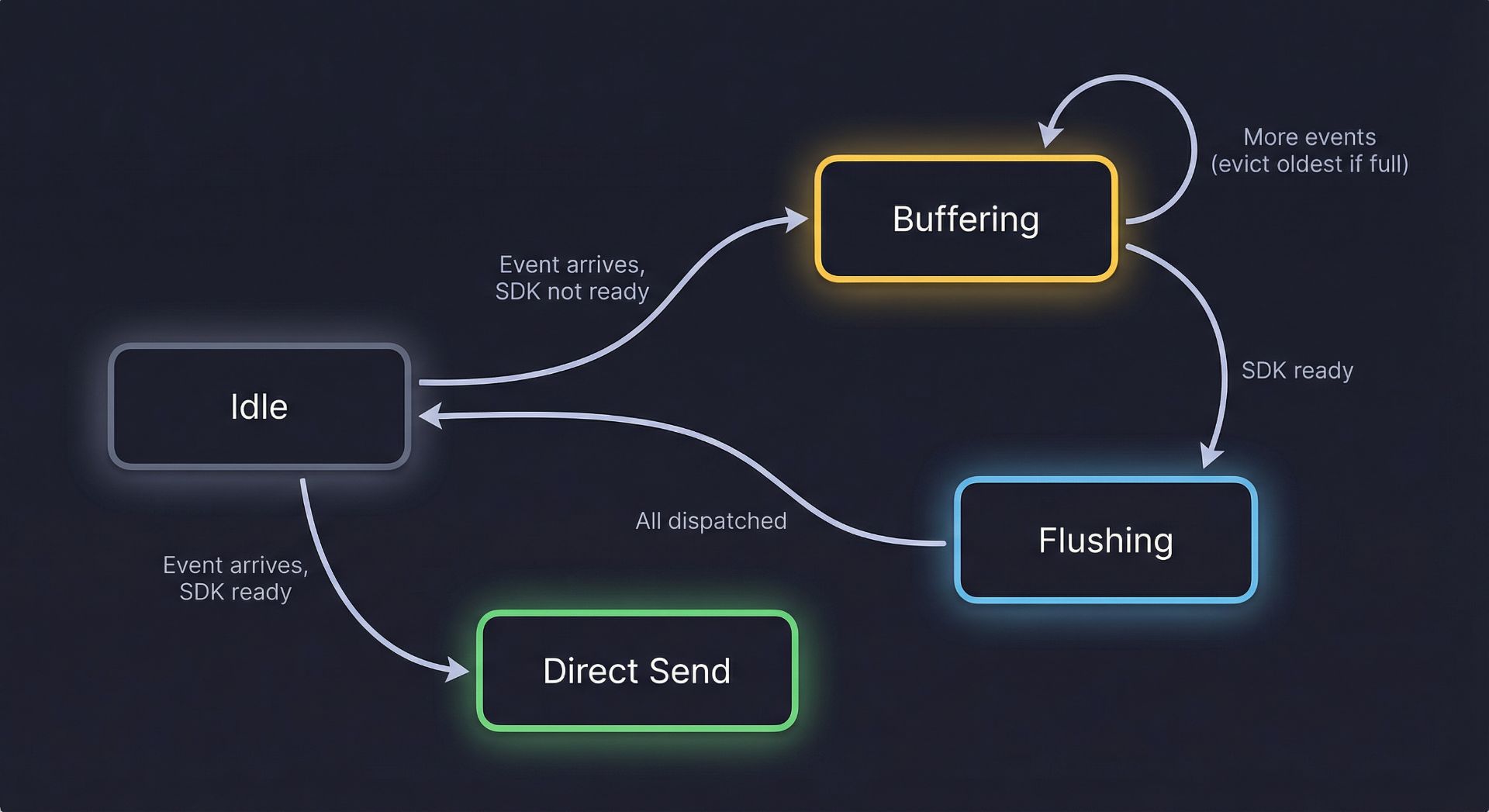
Frontend EngineeringFeb 20, 2026
Event Buffering: What It Is and How It Can Be Used in Your Analytics Pipeline
Not every system is ready to listen the moment something worth capturing happens. Event buffering is the practice of temporarily storing events until the consuming system is prepared to receive them — turning a race condition into a guarantee. This article introduces the pattern, explains when and why it's needed, and walks through how it works.
By Aya Jafar
JSData Buffer

Data EngineeringAug 13, 2025
End-to-End Data Quality Architecture with Great Expectations — From Validation to Resolution
A complete, production-proven architecture for continuous data quality validation that goes beyond detection. The system automates the full lifecycle of a data issue — from rule creation by multiple teams, through daily scheduled validation against a data warehouse, to real-time alerting and automatic issue creation routed to the right team's backlog. Includes operational guidance on upgrading to Great Expectations 1.x, building Data Docs efficiently, and setting storage retention policies. Runs for under $5/month with no dedicated infrastructure.
By Hameed Mahmood Salih
GreatExpectationsData Quality
Data EngineeringAug 13, 2025
Automating Search Engine Index Ingestion to OpenMetadata Using Python SDK
A step-by-step guide to discovering search engine collections and registering them as search index entities in OpenMetadata using the Python SDK. Covers field type mapping, sample data extraction, and idempotent sync — bringing search engine metadata into your governance catalog alongside databases, pipelines, and dashboards.
By Hameed Mahmood Salih
OpenMetadataSearch Engine
Data EngineeringJul 7, 2025
Automating Custom Data Pipeline Service Ingestion to OpenMetadata Using Python SDK
A practical guide to programmatically ingesting pipeline metadata from custom orchestrators into OpenMetadata using its Python SDK. Covers creating pipeline services, registering pipelines, and syncing task-level metadata — applicable to Prefect, Dagster, or any orchestrator with a REST API.
By Hameed Mahmood Salih
OpenMetadataData Orchestrator

Software DevelopmentJun 17, 2025
Fixing Missed Events in a Laravel Event-Driven System with Redis Consumer Groups
Understanding the core functionality of your tools — and the features they already provide — can save you valuable time and lead to cleaner, more reliable solutions. Often, the best fix isn’t rewriting logic, but fully leveraging the capabilities that are already built in.
By Ibrahim Ismail
redis-streamslaravel

Data EngineeringMay 7, 2025
Understanding Binary Logs in Amazon RDS MySQL: A Practical Guide to Database Change Data Capture
In Amazon RDS, binary logs (binlogs) serve as critical components for recording all changes to your database, including INSERT, UPDATE, and DELETE operations. These logs enable essential functionality such as replication, point-in-time recovery, and change data capture (CDC).
By Hameed Mahmood Salih
CDCMySQL

Data EngineeringDec 28, 2024
Open Metadata vs. DataHub: Choosing the Right Data Catalog Tool for Your Team
OpenMetadata and DataHub are both open-source platforms. Both tools offer similar functionalities for data cataloging, search, discovery, governance, and quality.
By Hameed Mahmood Salih
governancedatahub