Over-Partitioning Can Kill Your Analytics Warehouse Performance and Inflate Your Costs
Choosing too fine a partition granularity in a columnar analytics warehouse silently accumulates memory pressure through part metadata overhead, merge churn, and allocator fragmentation. This article explains why over-partitioning happens, how the three cost mechanisms compound each other, and how switching to a coarser partition period eliminates the problem — without changing a single query.
Over-Partitioning Can Kill Your Analytics Warehouse Performance and Inflate Your Costs
Why choosing too fine a partition granularity quietly drains memory, stalls merges, and pushes you toward an unnecessary infrastructure upgrade.
Partitioning in a columnar analytics warehouse is one of those features that feels harmless until it isn't. You pick a daily partition key because it seems reasonable — one partition per day, clean and organized. Months later, your active part count is in the tens of thousands, your merge queue never settles, and you're staring at a forced tier upgrade.
This article explains why over-partitioning happens, how it compounds into a serious cost and performance problem, and how to fix it — without changing a single query or losing any functionality.
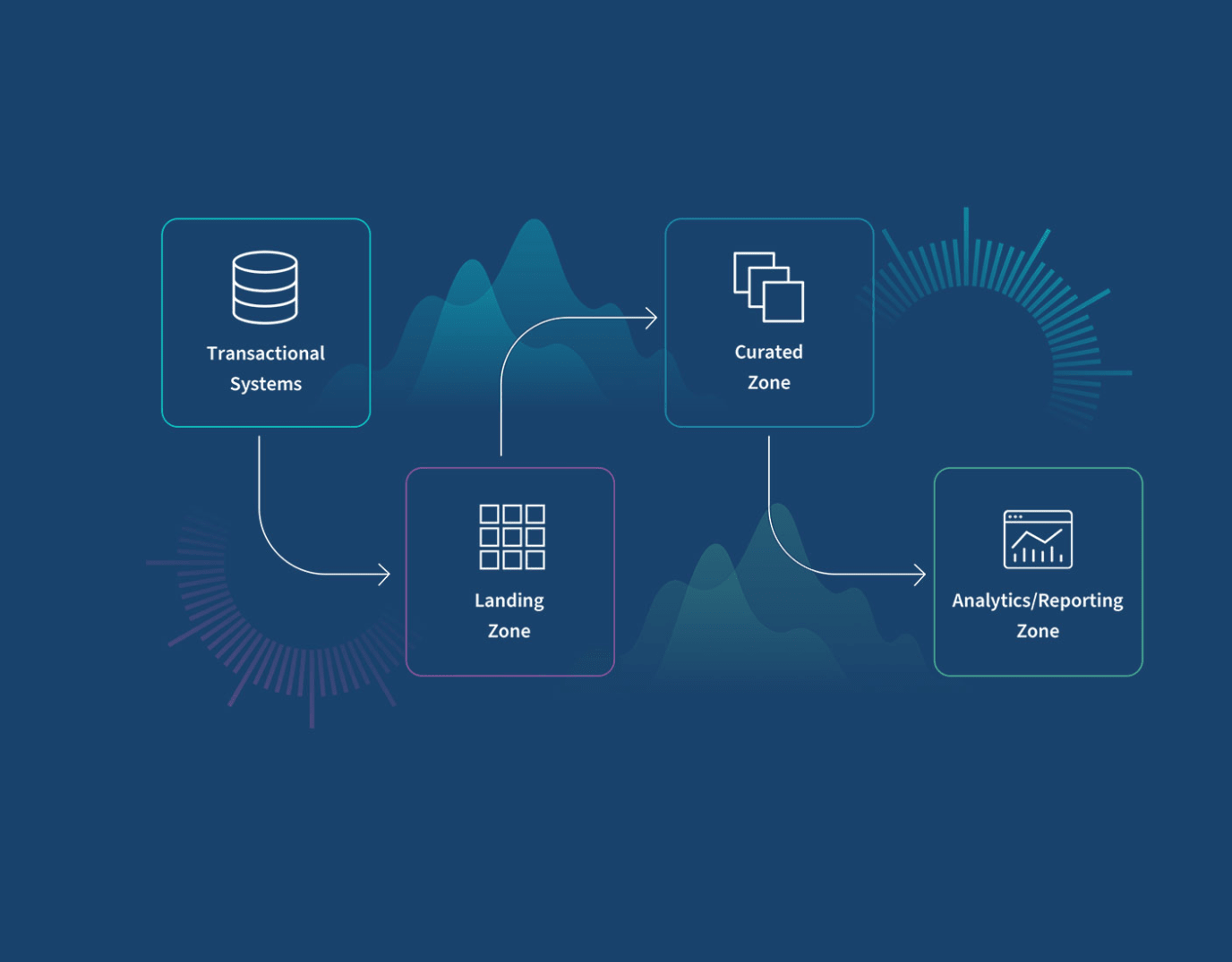
What Is a Partition and Why Does It Matter?
In a columnar analytics warehouse, a table is physically divided into parts — immutable chunks of data written to disk when rows are inserted. Parts within the same partition are periodically merged together by a background process into larger, more efficient files. Partitions are the merge boundary: the warehouse can only merge parts that share the same partition key value. Parts in different partitions never merge with each other.
This boundary is what makes partition granularity so consequential. Choose a coarse partition key (monthly, yearly) and merges consolidate data aggressively into a small number of large, efficient files. Choose a fine partition key (daily, or worse, hourly) and merges are confined to narrow windows — the warehouse ends up with hundreds of partitions, thousands of parts, and a merge process that can never fully catch up.
The Three Cost Mechanisms of Over-Partitioning
Over-partitioning has three distinct cost vectors, each compounding the others.
1. Direct Cost: Part Metadata
Every active part carries metadata in memory: column statistics, min/max indexes, mark file references, and checksums. This overhead is small per part, but it scales linearly with part count. A table with thousands of active parts holds a meaningful amount of RAM permanently occupied by metadata that describes files — not the data itself.
2. Indirect Cost: Merge Pressure
The warehouse continuously merges small parts into larger ones in the background. With thousands of parts spread across hundreds of narrow partitions, the merge scheduler is permanently active — allocating and releasing temporary buffers for every merge operation. This churn is invisible in part count statistics but very visible to the memory allocator.
3. Hidden Cost: Allocator Fragmentation
This is typically the largest contributor. The constant allocation-and-release cycle of merges causes memory allocator fragmentation — the growing gap between memory the allocator has reserved from the OS and memory it is actually using productively. This fragmentation shows up as resident memory you are paying for but cannot use.
The cascade: fine partitions → too many parts → constant merge churn → allocator fragmentation → inflated resident memory → forced tier upgrade.
Why Over-Partitioning Costs You Money Beyond Memory
The memory problem is a symptom. The downstream effects are broader:
Slower merges. More parts means more merge work. When merges cannot keep up with ingestion, part counts keep climbing, which degrades query performance — the warehouse must read from and merge results across many small files instead of a few large ones.
Higher disk usage. Small parts compress poorly. Columnar compression codecs work best on large data blocks. When data is fragmented across thousands of small parts, compression ratios suffer and storage costs rise.
Query overhead. Each query must open file handles, read mark files, and check min/max indexes for every relevant part. A partition with 100 active parts does 100 times the metadata work compared to a well-merged partition with a single part. This overhead is invisible on small datasets but compounds with table size.
Write limits. Most columnar warehouses impose limits on how many partitions a single insert can touch. If your partition count grows large enough, backfill operations — which naturally span wide date ranges — start failing outright.
Choosing the Right Partition Period
The right partition period is not a universal answer. It depends on the table. What you want is enough partitions to make TTL drops and selective partition operations tractable, but few enough that merges stay healthy and part counts stay manageable.
Factors to weigh:
- Data volume. A table ingesting billions of rows per day might justify monthly partitions. A low-volume dimensional table might do better with a single static partition or yearly.
- Read patterns. If queries almost always filter by date range, the primary key handles pruning within partitions — partition boundaries don't need to match query boundaries. The warehouse prunes within a partition using the sort key just as effectively.
- Write patterns. If you backfill or reprocess by date range, the partition period should align with how you batch those operations.
- Retention policy. If you drop data after 90 days, monthly is the natural choice. If you keep data for years and rarely drop, quarterly or yearly may be sufficient.
The rule of thumb: partition periods should produce tens of partitions per table, not hundreds. Daily partitioning on a high-volume event table will almost always produce hundreds of partitions within months. Monthly partitioning on the same table produces twelve per year.
Daily partitioning is rarely the right answer for event data. The common justification is "we might need to drop a specific day," but in practice, TTL policies handle data expiration at the partition level regardless of granularity, and the table's primary key (typically starting with a timestamp column) provides query pruning within a partition that is just as effective as a partition boundary.
How to Detect Over-Partitioning
Signs you are over-partitioned:
- Parts per partition consistently above 10. Merges are not keeping up with ingestion at the current partition granularity.
- Hundreds of unique partitions in a single table. Each is a merge boundary the warehouse can never cross.
- Resident memory higher than data volume or index size explains. The gap is likely merge churn and allocator fragmentation.
- Merge queue that never drains. Background merges are permanently active because the part count regenerates faster than merges can consolidate.
- Part count trending upward month over month despite stable data volume. This means equilibrium has never been reached.
Most columnar warehouses expose part and partition statistics through system tables or monitoring endpoints. A query that groups active parts by table and computes parts-per-partition will surface the problem immediately.
The Fix: Coarser Partition Key
The change is conceptually simple: replace a fine-grained partition expression with a coarser one. For high-volume event tables, daily → monthly is usually the right move. For lower-volume tables, consider quarterly or yearly.
The migration pattern:
- Create a new table with identical schema but a coarser
PARTITION BYexpression - Backfill:
INSERT INTO new_table SELECT * FROM old_table - Verify row counts match exactly
- Rename the new table into place, keeping the old one as a backup
- Drop the backup after monitoring confirms stability
Migrate table by table. Don't attempt batch DDL operations across all tables simultaneously.
What to Expect After Migration
Memory does not drop in a single step. There are two phases:
Immediate — Part metadata and live merge overhead disappear as soon as the new table takes over. This is visible within hours.
Gradual — Allocator fragmentation reclaims over days to weeks as the memory allocator's decay timers fire and fragmented pages are returned to the OS. A check 24 hours after migration will significantly understate the final savings. Re-measure at one month and three months.
Parts-per-partition is the operational signal that matters most after migration. A healthy table should converge to single-digit parts per partition once background merges complete. If it stabilizes there, the system has reached equilibrium under the new partition granularity.
Key Takeaways
Fine-grained partitions are a deferred cost, not a free feature. The overhead is invisible at first and grows silently as data accumulates.
The memory cost of parts is mostly indirect. Direct metadata per part is small. The cascade — merge pressure → temporary allocations → allocator fragmentation — amplifies the real cost by an order of magnitude.
Partition granularity should match the table, not the calendar. Monthly is a good default for high-volume event tables, but the right answer depends on volume, retention, and query patterns. The target is tens of partitions per table.
Measure, wait, then measure again. Memory allocators operate on longer timescales than a quick before/after comparison captures. Decay timers, page reclamation, and merge cycle completion all take time. The real savings materialize over weeks, not hours.
The best partition key is the coarsest one that still meets your operational requirements. Start coarse and go finer only if TTL granularity or selective drop operations genuinely require it. Going the other direction — from daily to monthly — requires a full table migration.

Written by
Hameed Mahmood Salih
Data Engineer